Main Results · Table 3
Explicit planning wins across every backbone.
Per-model, the same backbone acts as both planner and executor. Table F1 is the primary metric; SCoPE (ours) is the best row for each column. The biggest lift lands on the weakest implicit reasoner, Qwen3.
Grounded row-level reasoning accuracy
| Method | Qwen3 | Llama-3.3 | GPT-OSS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1 | RJ | FM | F1 | RJ | FM | F1 | RJ | FM | |
| BlendSQLTabular / structured | 11.56 | 6.52 | 20.63 | 5.60 | 5.15 | 5.81 | 7.30 | 6.48 | 7.71 |
| EHRAgentTabular / structured | 32.99 | 29.79 | 33.74 | 30.99 | 28.07 | 31.69 | 34.85 | 31.23 | 35.65 |
| Zero-ShotPrompting | 56.32 | 44.95 | 62.73 | 66.96 | 54.55 | 72.04 | 73.50 | 61.05 | 77.47 |
| CoTPrompting | 55.37 | 44.65 | 61.93 | 70.87 | 57.83 | 75.15 | 74.17 | 61.77 | 78.05 |
| Few-ShotPrompting | 54.74 | 44.09 | 61.48 | 69.38 | 56.56 | 74.05 | 73.99 | 61.55 | 77.85 |
| TableGPT2Table model · single, no backbone split | Single table model. F1 44.03 · RJ 33.78 · FM 50.81 | ||||||||
| SCoPE Ours · Best | 63.19 | 52.07 | 69.45 | 70.87 | 60.66 | 76.12 | 74.31 | 62.48 | 78.27 |
Higher is better on all metrics, and values are shown after one-to-one row alignment. The marks the best value in each column. SCoPE leads every backbone on all three metrics, matching the best prompting baseline on Llama-3.3 Table F1 (70.87).
Table F1 by method & backbone
Primary metric. SCoPE (highlighted) tops every backbone group. Few-Shot and TableGPT2 are left out here to keep it readable, so check the full table above for those.
Why this is hard · Figure 1
The answer isn't in the table. It has to be derived.
SCoPE reasons from inferred data present in visible rows through normalization, extraction, and a bit of light domain reasoning.
For Pembrolizumab trials, list the additional agents in the treatment regimen beyond the ICI.
| NCT | Treatment Regimen | Added Agents |
|---|---|---|
| NCT02039674 | Pembrolizumab + Pemetrexed + Carboplatin | ["pemetrexed", "carboplatin"] |
| NCT02578680 | Pembrolizumab + Platinum agent | ["platinum agent"] |
| NCT02358031 | Pembrolizumab + Platinum agent + 5-Fluorouracil | ["platinum agent", "5-fluorouracil"] |
| NCT03066778 | Pembrolizumab + Etoposide + Platinum agent | ["etoposide", "platinum agent"] |
| NCT02574598 | Pembrolizumab + Docetaxel | ["docetaxel"] |
Every agent in the Treatment Regimen other than Pembrolizumab, for example [Pemetrexed + Carboplatin]. The dashed gold column is worked out row by row from the visible evidence, and the model never sees it.
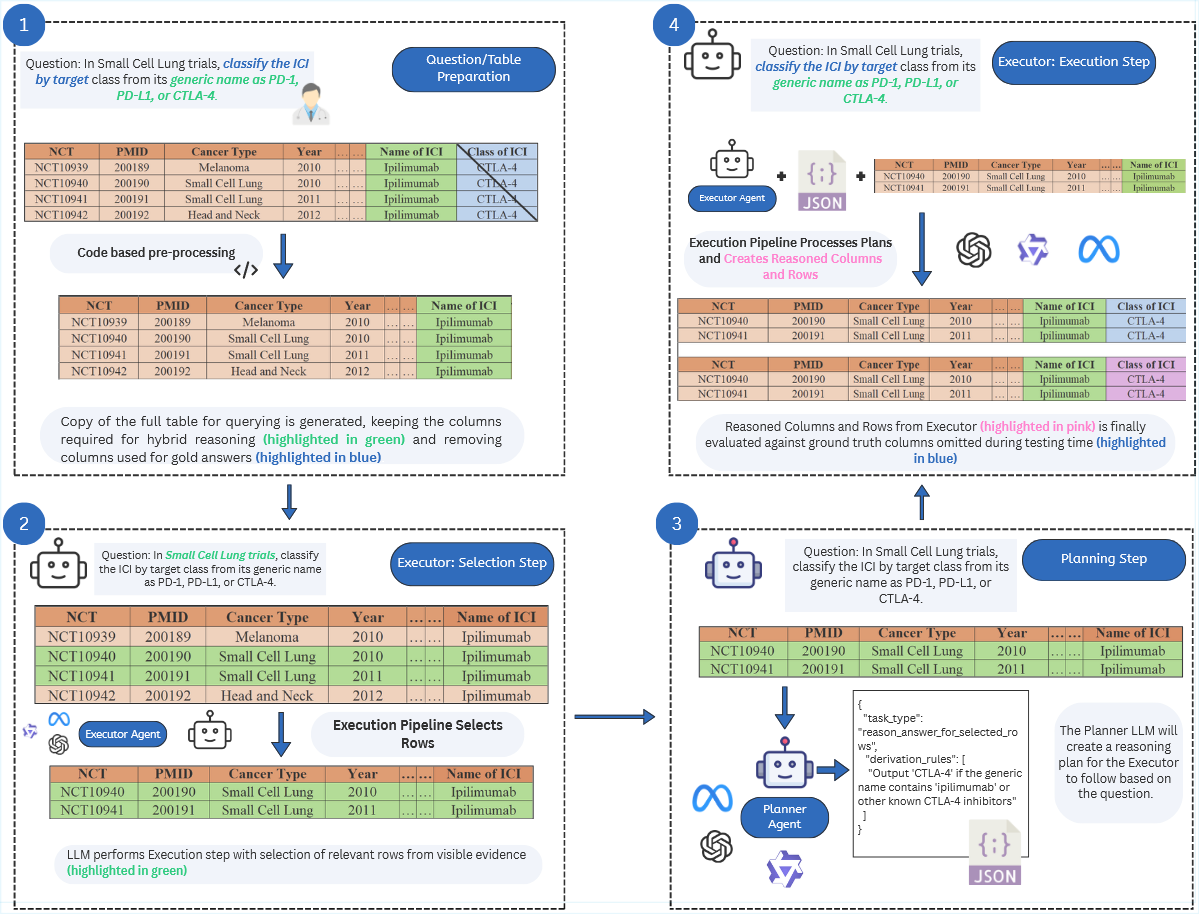
How SCoPE works · 3 stages
Select the rows, write the plan, execute against evidence.
Planning pulls apart three decisions that normally get tangled together, row grounding, source-field identification, and transformation. Under direct prompting, any one of them can quietly go wrong on its own.
Find the relevant rows
Identify the candidate subset of rows relevant to the question from the full visible table.
Emit an explicit JSON plan
A machine-checkable plan naming the inferred source column, relevant columns, and the rules for deriving the answer.
Produce row-aligned answers
Follow the plan to generate row-aligned predictions strictly from visible evidence.
The benchmark · Tables 1 & 2
Compact, but information-dense.
1,500 hybrid reasoning questions over a single living-evidence oncology table, where every target is derived deterministically from the visible evidence and then held out at inference.
How the 1,500 questions were built
Seeds authored by a certified oncology researcher over the IOTOX living-evidence table (years 2010-2021). Targets are derived deterministically from visible evidence and held out at inference time.
Answer-type distribution
1,500 questions across four answer types.
Ablations · Tables 4 & 5
A stronger planner lifts a fixed executor.
Mixing planner and executor backbones shows where the gains actually come from, and it shows that constrained grounded execution beats compiling the plan into code.
Cross-model, planner and executor differ
Table 4 · F1 / RJ / FM
| Executor | Planner | F1 | RJ | FM |
|---|---|---|---|---|
| GPT-OSS | Qwen3 | 75.07 | 63.74 | 79.26 |
| Qwen3 | GPT-OSS | 59.59 | 48.26 | 66.32 |
| Qwen3 | Llama-3.3 | 62.47 | 51.40 | 68.88 |
| GPT-OSS | Llama-3.3 | 75.12 | 63.88 | 79.28 |
| Llama-3.3 | GPT-OSS | 68.01 | 57.37 | 73.64 |
| Llama-3.3 | Qwen3 | 71.43 | 61.33 | 76.64 |
Planner → coder baseline
Table 5 · compile the plan to Python instead of grounded LLM execution
| Coder model | F1 | RJ | FM |
|---|---|---|---|
| GPT-OSS | 14.56 | 11.67 | 23.39 |
| Qwen3 | 48.92 | 37.53 | 56.01 |
| Llama-3.3 | 63.40 | 51.55 | 69.10 |
Efficiency · Figure 3
On the accuracy-cost frontier.
Tokens per question vs. Table F1 (Qwen-based). SCoPE reaches ~63% F1 for only a modestly larger token budget than direct prompting.
Sits on the best accuracy-cost frontier, around 63% Table F1 for only a modestly larger token budget than direct prompting.
Cluster around 28k to 30k tokens but stay in the mid-50s on F1.
Cheap, but much less accurate.
Both the most expensive and the weakest.
Error analysis · Table 6
Where planning helps, and where it doesn't.
SCoPE (GPT-OSS executor, Llama-3.3 planner) vs. GPT-OSS CoT, by question intent. Positive means SCoPE is better. Bars show ΔF1; gains concentrate on schema-grounding-heavy intents.